Knowledge Hub
Enhance your website with AI-powered semantic search using Chroma DB with Astro integration
Introduction
In this article, we will explore the powerful combination of Astro and Chroma to create a vector search functionality. We will walk through the process of initializing Astro and creating MDX content for our blog. Then, we will install and set up Chroma, a open-source database specifically designed for vector search. Furthermore, we will create a script to automate embeddings generation and data insertion into Chroma.
Next, we will guide you on creating an Astro API endpoint for Chroma vector search, enabling seamless search capabilities within your Astro application. Additionally, we will showcase how to create an autocomplete search element, leveraging the vector search features provided by Chroma.
By the end of this article, you will have a comprehensive understanding of how to integrate Astro and Chroma to implement vector search functionality in your projects.
In the digital age, even small blogs and marketing websites with fewer than 100 articles need efficient search solutions. However, for these predominantly static sites, investing in expensive paid search systems may not always be justifiable.
This is where modern generative AI solutions come into play, offering a cost-effective and advanced alternative to traditional search systems like Algolia or ElasticSearch.
Key benefits of these AI-driven search tools include:
- Contextual understanding - they comprehend the context of your content, making searches more relevant.
- Personalized search results - AI algorithms can tailor search results based on user behavior, preferences, and past interactions, offering a more personalized experience.
- Dynamic content indexing - AI-driven search engines can adapt to content changes more rapidly, ensuring that the search results are always up-to-date and relevant.
- Typo correction - automatic correction of typos in search queries.
- Accurate ranking - enhanced ranking algorithms that consider the importance of terms in the context of each article, improving search accuracy.
These features collectively enhance user experience and search efficiency on your website.
What we will cover
In this guide, we will take you through the process of enhancing your website's search capabilities using Chroma. Our journey will include:
- Building an Astro blog - we'll start by creating an Astro blog that hosts a variety of technical articles on diverse topics. This will serve as our base for implementing the search features.
- Automating vector search database indexing - once our website is built, we'll focus on automatically building a vector search database index for Chroma. This step is crucial for powering our AI-driven search tool.
- Creating an API endpoint for search - finally, we will develop an API endpoint. This endpoint will leverage the previously created index to conduct searches, effectively utilizing Chroma’s capabilities to enhance the search experience on our blog.
Introduction to Chroma DB
Chroma is an open-source, AI-powered search engine designed specifically for small applications. It is akin to SQLite in the traditional database world, operating efficiently alongside your application with minimal resource requirements.
Key Features:
- Intelligent search functionality - Chroma is adept at understanding the context of content, ensuring search results are both accurate and relevant.
- Developer-friendly experience - it offers an intuitive search experience, making it accessible for users of all technical levels.
- Efficiency - as a lightweight solution, it runs smoothly in local environments, making it ideal for applications that require a compact yet powerful search tool.
Understanding the mechanics of semantic search
Semantic search represents a significant leap beyond traditional keyword-based search, delving into the deeper meaning and context of search queries using NLP techniques. Let’s break down some key concepts to understand how it works.
What are embeddings?
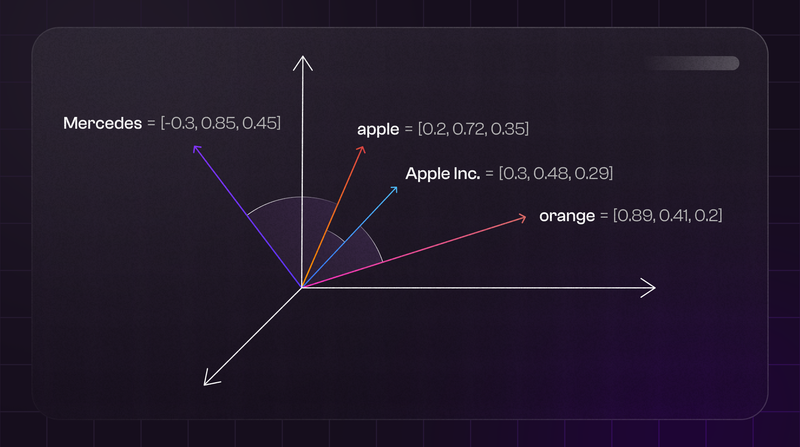
Imagine every word or phrase as a unique point in an expansive galaxy. In this space, points that share similar meanings are positioned closer to each other. For example, in our metaphorical galaxy, 'apple' (the fruit) and 'orange' are neighboring points, illustrating their shared context as fruits.
Interestingly, 'apple' (the fruit) and 'iPhone’ still share a certain proximity (although not as close as 'apple' and 'orange').
Why? Because they are linked through the common entity of Apple Inc. In contrast, an entirely unrelated concept like 'Mercedes' would be much farther from 'apple' in this spatial representation.
This galactic representation helps us understand how embeddings group words by meaning and context, rather than just by their literal appearance. It's a crucial part of what makes semantic search engines so powerful in understanding and interpreting the nuances of language.
Understanding cosine similarity
Cosine similarity is essential in semantic search, as it measures the similarity between two embeddings by calculating the cosine of the angle between their vectors. This metric ranges from -1 (completely different) to 1 (exactly the same).
For instance, consider two word vectors: A (10, 20) and B (1231, -1231). In JavaScript, the cosine similarity can be calculated as follows:
function cosineSimilarity(A, B) {
const dotProduct = A.reduce((sum, a, i) => sum + a * B[i], 0);
const normA = Math.sqrt(A.reduce((sum, a) => sum + a * a, 0));
const normB = Math.sqrt(B.reduce((sum, b) => sum + b * b, 0));
return dotProduct / (normA * normB);
}
// First pair of vectors (more similar)
let vectorA1 = [10, 20];
let vectorB1 = [10, 15];
let similarity1 = cosineSimilarity(vectorA1, vectorB1);
console.log("Cosine Similarity for Pair 1: ", similarity1);
// "Cosine Similarity for Pair 1: ", 0.9922778767136676
// Second pair of vectors (less similar)
let vectorA2 = [10, 20];
let vectorB2 = [1231, -1231];
let similarity2 = cosineSimilarity(vectorA2, vectorB2);
console.log("Cosine Similarity for Pair 2: ", similarity2);
// "Cosine Similarity for Pair 2: ", -0.31622776601683794Hands-on example: exploring the mythical universe
In this example, we will demonstrate how our powerful search engine allows users to explore the mythical universe of ancient deities from Greek and Nordic mythologies.

- Initializing project structure
- Installing and setting up Chroma
- Creating a script for embeddings generation and data insertion
- Creating an Astro API endpoint for Chroma vector search
- Creating an autocomplete search element
1. Initialize project structure with AstroJS
We will start by setting up an Astro project using the minimal template. To begin, run the command yarn create astro in your preferred terminal, which will create an empty Astro project for you.
Once the project is initialized, navigate to the newly created project directory and locate the src folder. Inside the src folder, we will add the following additional folders and files:
├── src
│ ├── content
│ │ └── posts
│ │ ├── greeks
│ │ │ ├── zeus.mdx
│ │ │ └── hermes.mdx
│ │ └── nords
│ │ ├── odin.mdx
│ │ └── thor.mdx
│ ├── components
│ │ └── search.tsx
│ ├── layout
│ │ └── main-layout.astro
│ └── pages
│ ├── api/search.ts
│ └── posts/[...slug].astro
│
├── index-builder.js
└── ...- Content: this folder will contain the content for our blog about ancient deities of Greek and Nordic mythologies. We can organize it into sub-folders based on different categories, such as Greek deities and Nordic deities. Articles are going to have the following template:
---
title: "Hermes: The Swift Messenger of the Gods"
date: "2023-12-26"
author: "Aren Hovsepyan"
slug: hermes
---
# Hermes: The Swift Messenger of the Gods
Hermes, an Olympian deity in Greek mythology, is renowned for his speed, wit,
and versatility. As the messenger of the gods, his roles and symbolism extend
to various realms.- Pages: this folder will contain our
api/searchendpoint for handling search requests, as well as pages for our blog posts. - Layouts: this folder will hold the main layout file for your blog.
- Components: in this folder, we can store our
search.tsxReact element for autocomplete element. Later on you can add other components under this file. - Index-builder.js: this file is responsible for generating an index from the stored MDX data and inserting them into Chroma with OpenAI embeddings.
2. Install Chroma DB on your machine
To install Chroma, you have two straightforward options depending on your preference.
Option 1: Using pip (Python Package Installer)
Make sure you have pip installed in your Python library. If you don't have pip installed, you can easily install it by following the appropriate steps for your operating system.
After ensuring pip is available, open your terminal or command prompt and run the following command to install Chroma:
pip install chromadbOption 2: Cloning the Chroma DB GitHub repository
If you prefer to clone the Chroma GitHub repository and run it using Docker, follow these steps:
1. Open your terminal or command prompt. Navigate to your desired directory where you want to clone the repository. Run the following command to clone the repository:
git clone <https://github.com/chroma-core/chroma>2. Once the repository is cloned, navigate into the cloned directory:
cd chroma3. Run the following command to start Chroma using Docker Compose. This will start the ChromaDB service in the background.
docker-compose up -dWith either of these installation methods, you should now have Chroma up and running, ready to power your search engine and provide closely related items in the proper rank.
3. Build Chroma DB index for our posts
To get started with Chroma, we'll first need to install the Chroma package adapter via the Yarn command:
yarn add chromadbThis will allow us to interact with the Chroma server and build our index. Let's set up an index-builder.js file and create a getPosts function that fetches all .mdx files under a content folder and convert them to JSON format using the gray-matter package.
Here's the implementation of the getPosts function:
import path from "path";
import { glob } from "glob";
import { promises as fs } from "fs";
import matter from "gray-matter";
async function getPosts() {
const pathToContent = path.join(process.cwd(), "content/**/*.mdx");
const files = await glob(pathToContent);
const posts = await Promise.all(
files.map(async (file) => {
const content = await fs.readFile(file, "utf8");
return matter(content);
})
);
return posts;
}After converting the .mdx files to JSON format using the gray-matter package, the next step is to initialize the Chroma client. This can be done by importing the Chroma package and creating a client instance. Next, we need to create a collection called posts using createCollection method. This will let us interact with the posts collection.
Note that we use deleteCollection before creating a new collection to remove stale data for subsequent calls of index-builder.js script.
import { ChromaClient, OpenAIEmbeddingFunction } from "chromadb";
async function main() {
const posts = await getPosts();
const client = new ChromaClient();
// special class which will be passed to client and automatically create embeddings
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: process.env.OPENAI_API_KEY,
});
const COLLECTION_NAME = "posts";
// delete collections to remove stale records and rebuild with up to date data.
await client.deleteCollection({ name: COLLECTION_NAME });
// create a collection
// note that we pass embedder that will automtically create embeddings
// with OpenAI Embeddings API
const collection = await client.createCollection({
name: COLLECTION_NAME,
embeddingFunction: embedder,
});
}Lastly, we add our posts into posts collection using client.add method.
// feed data into new collection
// note that we don't pass embeddings, however they will be created behind the scenes
await collection.add({
ids: posts.map((i) => i.data.slug),
metadatas: posts.map((i) => i.data),
documents: posts.map((i) => i.content),
});Here’s the full code:
import "dotenv/config";
import path from "path";
import { glob } from "glob";
import { promises as fs } from "fs";
import { ChromaClient, OpenAIEmbeddingFunction } from "chromadb";
import matter from "gray-matter";
async function getPosts() {
const pathToContent = path.join(process.cwd(), "src/content/**/*.mdx");
const files = await glob(pathToContent);
const posts = await Promise.all(
files.map(async (file) => {
const content = await fs.readFile(file, "utf8");
return matter(content);
})
);
return posts;
}
async function main() {
const posts = await getPosts();
const client = new ChromaClient();
// special class which will be passed to client and automatically create embeddings
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: process.env.OPENAI_API_KEY,
});
const COLLECTION_NAME = "posts";
// delete collections to remove stale records and rebuild with up to date data.
await client.deleteCollection({ name: COLLECTION_NAME });
// create a collection
// note that we pass embedder that will automtically create embeddings
// with OpenAI Embeddings API
const collection = await client.createCollection({
name: COLLECTION_NAME,
embeddingFunction: embedder,
});
// feed data into new collection
// note that we don't pass embeddings, however they will be created behind the scenes
await collection.add({
ids: posts.map((i) => i.data.slug),
metadatas: posts.map((i) => i.data),
documents: posts.map((i) => i.content),
});
}
main();4. Search via JSON API
To handle requests that will later come from our UI and allow users to interactively search certain posts, we need to create a JSON endpoint in Astro. This endpoint will be responsible for handling the search requests and providing the necessary data.
To get started, ensure that you have enabled the output: hybrid configuration in your astro.config.mjs file. This configuration is necessary to opt out from static mode and accept dynamic requests with search params.
Here is the full configuration file with the necessary imports and settings for Astro:
import { defineConfig } from "astro/config";
import tailwind from "@astrojs/tailwind";
import react from "@astrojs/react";
import mdx from "@astrojs/mdx";
export default defineConfig({
output: "hybrid",
integrations: [tailwind(), react(), mdx()],
});This file imports the required modules (tailwind, react, mdx) from Astro and defines the configuration using defineConfig.
Next, we can proceed to build the JSON endpoint functionality in Astro. This will involve handling the search requests, querying the necessary data source, and returning the results in JSON format.
First, we need to create a file in pages/api folder called search.ts . Based on Astro file routing this will let us send GET requests to /api/search endpoint.
To create embeddings vectors from the user query and match them with our post embeddings, we need to initialize our embedder and collection objects. In Chroma, cosine similarity is used to compare the two embeddings vectors.
While we can use OpenAI embeddings for this example, you also have the option to use HuggingFace embeddings models through a special wrapper provided by Chroma. This allows you to leverage HuggingFace's embeddings without relying on paid solutions. You can find more information about this in the Chroma documentation.
// we need to access OPENAI_API_KEY with vite helper method `loadEnv`
const { OPENAI_API_KEY } = loadEnv(
process.env.NODE_ENV as string,
process.cwd(),
""
);
const client = new ChromaClient();
const COLLECTION_NAME = "posts";
// initialize embedder to create embeddings from user query
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: OPENAI_API_KEY as string,
});
// note that instead of `createCollection` we use `getCollection`
const collection = await client.getCollection({
name: COLLECTION_NAME,
embeddingFunction: embedder,
});After successfully connecting to our Chroma server, we need to create an API route handler to accept incoming requests. It is important to handle corner cases in our route, such as when the query value is empty or has fewer characters than the required minimum for a meaningful word or phrase.
Here's how we can achieve this:
- First, we check if the query parameter is defined. If it is not defined, we send an error response to indicate that a query is required.
- Next, we check if the length of the query is less than 3 characters. If it is, we send an empty response. This can be useful when the query is too short to produce meaningful search results.
By implementing these checks in our API route handler, we ensure that our application handles these corner cases gracefully.
export const GET: APIRoute = async ({ url }) => {
const query = url.searchParams.get("query");
// through an error if query param is not defined
if (!query) {
return new Response(JSON.stringify("Please provide search query phrase"), {
status: 403,
});
}
// don'send empty reponse if query is less than 3 chars
if (query.length < 3) {
return new Response();
}
// query items in ChromaDB with give query phrase
const results = await collection.query({
nResults: 100,
queryTexts: url.searchParams.get("query") as string,
});
return new Response(JSON.stringify(results.metadatas[0], null, 2));
};Wait, now when we send a request using query search param, we get an empty string.
Here we need to simply set a prerender config variable to our route. This tells Astro that endpoint should always serve incoming requests.
export const prerender = false;Here is the full code of the API route:
import type { APIRoute } from "astro";
import { ChromaClient, OpenAIEmbeddingFunction } from "chromadb";
import { loadEnv } from "vite";
// we need to access OPENAI_API_KEY with vite helper method `loadEnv`
const { OPENAI_API_KEY } = loadEnv(
process.env.NODE_ENV as string,
process.cwd(),
""
);
const client = new ChromaClient();
const COLLECTION_NAME = "posts";
// initialize embedder to create embeddings from user query
const embedder = new OpenAIEmbeddingFunction({
openai_api_key: OPENAI_API_KEY as string,
});
// note that instead of `createCollection` we use `getCollection`
const collection = await client.getCollection({
name: COLLECTION_NAME,
embeddingFunction: embedder,
});
export const prerender = false;
export const GET: APIRoute = async ({ url }) => {
const query = url.searchParams.get("query");
// through an error if query param is not defined
if (!query) {
return new Response(JSON.stringify("Please provide search query phrase"), {
status: 403,
});
}
// don'send empty reponse if query is less than 3 chars
if (query.length < 3) {
return new Response();
}
// query items in ChromaDB with give query phrase
const results = await collection.query({
nResults: 100,
queryTexts: url.searchParams.get("query") as string,
});
return new Response(JSON.stringify(results.metadatas[0], null, 2));
};Cool, now we can go to a browser tab to visit the following URL http://localhost:4322/api/search?query=Sagas and we will see our JSON response.
Project repository and live demo
For those eager to delve deeper, explore our full codebase on our GitHub repository. Inspect the code and feel free to contribute! Also, you can check out the project through our live demo.
Conclusion
In summary, our exploration in this article has uncovered the incredible potential of AI-driven semantic search with Chroma. This technology offers transformative capabilities and significant cost-saving benefits. We've delved into the core components of this system, ensuring you have a solid grasp of its workings.
- Embeddings unveiled - we've revealed the importance of embeddings, which enable your website to better understand what users are looking for.
- Cosine similarity explained - we've explained the math behind cosine similarity, making it easier for your website to speak the same language as your users.
- Astro Integration - we've made it simpler to integrate AI into your Astro application, paving the way for an improved search experience.
- Chroma's streamlined process - we've simplified the process of creating search indexes with Chroma, making your website's search capabilities efficient and hassle-free.
- API for easy searching - we've also shown you how to integrate Chroma seamlessly through an API, giving your users powerful search tools.
Beyond saving costs, Chroma brings a more natural search experience. Users no longer need to worry about specific keywords, categories, or spelling errors because modern models handle these complexities behind the scenes.
This technology boosts user satisfaction, optimizes resource allocation, and transforms your website into a search-savvy destination. It's not just about saving money; it's about preparing your website for success in the age of AI. Don't miss the chance to unlock your website's full potential; the future of enhanced search experiences is right at your fingertips.