- 15 min to read
How to build a write-intensive system with Kafka and tRPC
Discover the power of combining Kafka and tRPC. This comprehensive guide will walk you through setup, integration, and optimization, combining Kafka's data streaming with tRPC's type-safe APIs for peak performance and resilience.


Introduction
In recent times, data has been more than just bytes and bits. It's the backbone of countless industries and the heart of many modern applications. Systems today are not just required to read large volumes of data. They must also handle massive write operations. This is where write-intensive systems are introduced. These systems prioritize the ability to record data rapidly and efficiently, often needing to cater to high-velocity data sources like IoT sensors, financial transactions, or social media activity feeds.
In between scalability and reliability lies Apache Kafka. Kafka is renowned for its durability, fault tolerance, and high throughput capabilities, especially when it comes to write-heavy workloads. As a distributed event streaming platform, it facilitates real-time data pipelines and stream processing. On the other hand, tRPC is a modern framework for building typesafe APIs, that amplifies the power of RPC (Remote Procedure Call) with TypeScript's static typing. It promises a robust way to create and manage APIs, ensuring efficient communication between services.
Queue as an alternative for building a write-intensive system
Before we dive deep into Kafka, it's worth noting that many systems leverage queuing mechanisms to handle write-intensive workloads.
In traditional systems architecture, queues have been the cornerstone of handling bursts of data and ensuring that backend systems aren't overwhelmed. They act as buffers, storing messages or data temporarily until the consuming system or service is ready to process them. This asynchronous nature of queues helps in decoupling the producing and consuming systems, thereby ensuring that the speed mismatches between producers and consumers don't lead to system overloads.
For instance, think of an e-commerce platform during a Black Friday sale. The influx of user activity and orders is huge. A simple database might not be able to handle the writes directly, but with a queue, the orders can be processed in a controlled manner without crashing the system.
An example of Queue software is RabbitMQ. It is an open-source message broker that supports multiple messaging protocols. RabbitMQ is known for its robustness, ease of use, and support for a wide range of plugins. Queues can absorb large bursts of write operations, serving as a buffer.
Where to use Kafka
Kafka, in many ways, is an evolution of this concept, bringing in additional benefits like durability, scalability, and the ability to stream data in real time.
While traditional queuing systems are effective, they have their limitations, especially when data persistence, ordering, and real-time processing are paramount. This is where Kafka shines.
- Data persistence - unlike many queuing systems where messages disappear after being consumed, Kafka retains messages for a configurable period. It allows for reprocessing or re-reading data, an essential feature for analytics and auditing purposes.
- Scalability - Kafka is designed to scale out by adding more nodes to the cluster. This distributed nature ensures that as data inflow increases, the system can handle the surge without significant architectural changes.
- Real-time streaming - beyond just queuing, Kafka is built for real-time data streaming. It is invaluable for applications that require immediate insights or actions based on incoming data.
- Fault tolerance - Kafka's distributed nature ensures that data is replicated across multiple nodes, providing fault tolerance. If a node fails, another can take over, ensuring data availability and system durability.
Real-world use cases
- LinkedIn - Kafka was developed at LinkedIn before it became an open-source Apache project. LinkedIn uses Kafka for activity tracking and operational metrics. Every interaction on the platform, like profile views, connections, and article reads, gets processed through Kafka to drive features like "Who viewed your profile" and feed personalization.
- Spotify - Spotify uses Kafka for tracking activity, operational metrics data, and music recommendations. Kafka helps in tracking user activities like song plays and interactions. This information powers features like "Discover Weekly," where Spotify curates a personalized playlist for listeners every week based on their musical tastes.
- Slack - Slack utilizes Kafka for its real-time messaging platform. Kafka powers the real-time analytics at Slack, helping them monitor, alert, and analyze their large-scale operations. This real-time processing ensures that users can chat without delays and that notifications are timely.
Given these strengths, Kafka is ideal for scenarios that involve real-time analytics, log aggregation, stream processing, and, of course, write-intensive systems where data durability and scalability are crucial.
The purpose and benefits of using Kafka and tRPC in building a write-intensive systems
Illustration of building a write-intensive system:
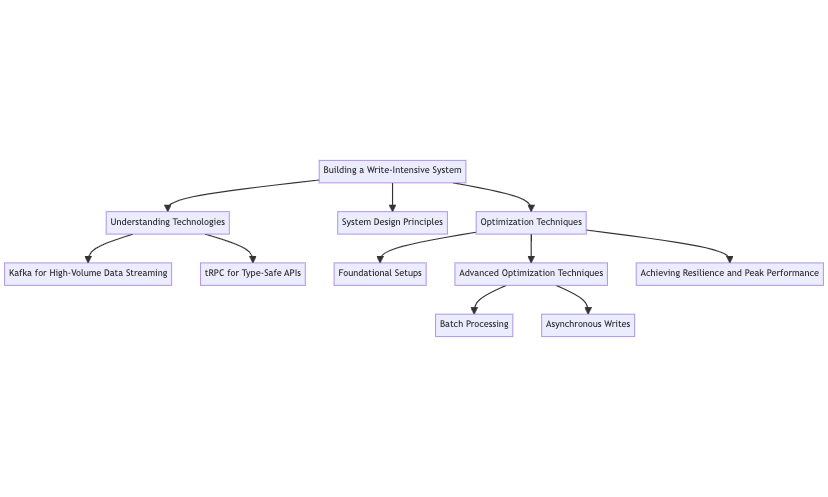
This diagram illustrates building a write-intensive system, emphasizing Kafka's data streaming and tRPC's type-safe APIs. It showcases foundational setups, optimization techniques, and the importance of resilience and peak performance.
Kafka provides a platform for handling vast amounts of data, but when it comes to interfacing or presenting that data to other systems, APIs become indispensable. tRPC's seamless integration with TypeScript, combined with its efficient and type-safe approach, complements Kafka's data-handling prowess. Together, they create a powerful ecosystem for building write-intensive systems.
Kafka's Strengths
- High throughput - Kafka can handle millions of events per second, making it perfect for write-intensive systems.
- Durability - data in Kafka is written to disk and replicated, ensuring that it remains safe and available, even in cases of hardware failures.
- Distributed processing - with its distributed nature, Kafka can spread data across a cluster, allowing parallel processing and thereby speeding up data handling.
tRPC's power
- Typesafe APIs - leveraging TypeScript's static typing, tRPC ensures that the API contracts are adhered to, reducing runtime errors.
- Efficient communication - tRPC provides optimized endpoints, ensuring that the data transferred between services is minimal and precisely what's needed.
- Seamless integration - tRPC's compatibility with modern frameworks allows developers to integrate it into diverse ecosystems, ensuring that whether it's in conjunction with Kafka or any other system, the API layer remains robust and efficient.
By combining Kafka's event streaming capabilities with tRPC's efficient API management, developers can build systems that not only handle massive write operations but also present this data to downstream services in a streamlined, typesafe, and efficient manner. The synergy between these tools provides a foundation that can support the demanding requirements of modern, data-heavy applications.
Write-intensive systems
In the evolving digital landscape, the demand for systems that primarily write data as opposed to reading it is surging. Such systems are the backbone for scenarios where real-time capture and processing of data are paramount.
Characteristics
- High throughput - these systems are designed to handle vast amounts of incoming data simultaneously
- Low latency - they prioritize rapid data processing and writing
- Durability - emphasis on ensuring data once written is not lost
- Scalability - as data inflow can be unpredictable, these systems should scale on demand
Challenges
- Data integrity - preventing data corruption during high-volume write
- Data ordering - ensuring that concurrent writes maintain a consistent order
- Resource management - allocating resources efficiently during peak data inflows
- Fault tolerance - ensuring the system remains operational even when certain components fail
Use cases
Financial transaction systems, large-scale logging systems, real-time analytics, telemetry data capture from thousands of IoT devices, and event-driven architectures.
System design considerations for write-intensive workloads
- Data distribution - efficient sharding or partitioning mechanisms to distribute data across multiple storage units or nodes
- Concurrency control - mechanisms like locks, semaphores, or versioning to handle simultaneous write operations
- Buffering - implementing caches or buffers to manage sudden spikes in data writes
- Feedback mechanisms - ensuring that producers receive immediate acknowledgments for their write operations, especially in systems where the confirmation of data write is critical
Apache Kafka overview
Kafka, born at LinkedIn and later donated to the Apache Software Foundation, has rapidly become the go-to platform for event streaming. With its distributed architecture, it's uniquely positioned to handle vast amounts of data with low latency. Its design, centered around the immutable commit log, ensures that data is stored sequentially, allowing multiple consumers to read data in real-time or retrospectively. It makes it ideal for applications like write-intensive systems and more. Learn more here.
Key Features
- Topic partitions - data in a topic is split across partitions, enabling parallelism and scalability
- Replication - data is replicated across multiple brokers for fault tolerance
- Offsets - consumers track their data reads using offsets, ensuring no data loss even after crashes
- Compact logs - older records can be pruned while preserving the latest version of a record, saving space
In a write-intensive system, the flow and volume of data are paramount. The producer-broker-consumer model of Kafka aligns perfectly with this:
- Producers - these are the data sources or applications that generate and push data. In the context of write-intensive operations, producers can be thought of as the initial gateways where data enters the system. They are equipped to handle sudden bursts of data, efficiently serialize it, and then send it to Kafka.
- Brokers - brokers are the heart of Kafka and serve as the storage and distribution mechanism. When data influx rates are high, brokers manage the efficient storage and replication of this data across a distributed architecture. They maintain order, ensure durability, and provide mechanisms to balance the load across the Kafka cluster.
- Consumers - as the name suggests, consumers pull data from Kafka for processing or downstream applications. In write-intensive systems, while the emphasis is on writing data, it's equally crucial that this data is available for immediate or eventual consumption. Kafka's consumer model, with its ability to track data reads using offsets and read from multiple partitions concurrently, ensures that data processing isn't bottlenecked.
tRPC overview
By leveraging the strengths of TypeScript, tRPC has revolutionized the RPC paradigm, ensuring type safety in client-server communications. In systems where the integrity and shape of data are critical, tRPC's enforcement of type consistency is invaluable. It simplifies API development, streamlines client-server interactions, and integrates seamlessly with modern frameworks. For write-intensive systems, where efficient and error-free data exchange is paramount, tRPC offers a robust solution. Learn more here.
Key features and benefits
- Simplified API development - traditional RESTful development requires careful management of endpoints. With tRPC's procedure-based approach, developers can focus on functionality rather than endpoint management.
- Full type safety - one of the standout features is its commitment to type safety. With TypeScript's static typing, tRPC ensures that the shape and type of data between client-server communications remain consistent, reducing runtime errors.
- Auto-generated client libraries - based on server procedures, eliminating the need for manual client-side API integrations.
- Efficiency - tRPC is optimized for performance, ensuring that data exchange is swift, reducing overheads, which is especially important in write-intensive scenarios.
- Flexibility - tRPC's ability to integrate with various back-end and front-end frameworks provides developers with a versatile tool tailored to a broad spectrum of applications.
Use cases
- Online gaming platforms - a multiplayer online game where players can interact, trade items, and form teams. The game’s backend might use tRPC to handle trade requests, team formations, or player interactions. Given that online games often need to handle a vast number of requests, the efficient nature of tRPC could be beneficial.
- Content Management Systems (CMS) - a CMS platform designed for media companies that host vast amounts of video content. Such a platform might utilize tRPC for its administrative interfaces, allowing content creators to upload, categorize, and manage their media with type-safe API calls, ensuring that metadata around each media item is consistent.
Role in the system
The efficient transmission and processing of data are critical in a write-intensive system. tRPC stands as the bridge ensuring that data flows seamlessly between services, databases, and clients. Its typesafe nature further guarantees that this data remains consistent and reliable, making it an invaluable tool in the realm of such demanding systems.
Hosted Kafka solutions
While setting up Kafka manually provides a great deal of control over your infrastructure, it's worth considering hosted Kafka solutions like upstash to simplify the process and reduce operational overhead, especially when building write-intensive systems. Hosted Kafka services offer several advantages that can enhance the efficiency and scalability of your data streaming setup.
Upstash is a Serverless Data Platform with Redis and Kafka support. It offers a comprehensive Kafka hosting service that simplifies the implementation of Kafka for various use cases, including write-intensive systems.
Benefits of hosted Kafka solutions
- Ease of setup - hosted Kafka solutions typically offer user-friendly interfaces that make Kafka setup accessible, even for those without extensive infrastructure management experience.
- Managed infrastructure - with hosted services, you can offload tasks like scaling, monitoring, and backups, allowing your team to focus on application development and logic.
- Security - many hosted Kafka services include built-in security features, ensuring data protection and compliance with security standards.
While hosted solutions offer compelling benefits, it's essential to note that the choice between a self-hosted Kafka setup and a hosted solution depends on your project's specific requirements. Factors like control, budget, and customization needs should guide your decision-making process.
Implementing the system with Kafka
Before you start, it's important to set things up correctly. For a self-hosted manual setup, you'll need to follow these steps:
Downloading Kafka
You can download Kafka from the official Apache Kafka website. Choose the appropriate version based on your requirements.
Installation
After downloading, you extract the Kafka binaries and navigate into the Kafka directory:
This command extracts the downloaded Kafka tarball and then changes the directory to the Kafka installation.
Configuration
Kafka configurations are mostly held in the config directory. For starters, you might need to adjust the broker settings in server.properties.
For example, to change the default port:
This configuration updates the Kafka broker to listen on port 9093.
Starting Zookeeper and Kafka
Kafka relies on Zookeeper for distributed cluster management. First, we start Zookeeper:
These commands first start the ZooKeeper, which Kafka uses for maintaining configurations and leadership elections among broker nodes. Following that, the Kafka broker itself is started.
Once Zookeeper is up, we initiate the Kafka server:
Creating Kafka producers in JavaScript
A Kafka producer sends messages (events) to Kafka topics.
Here's a flowchart illustrating the process of setting up a Kafka producer using JavaScript:
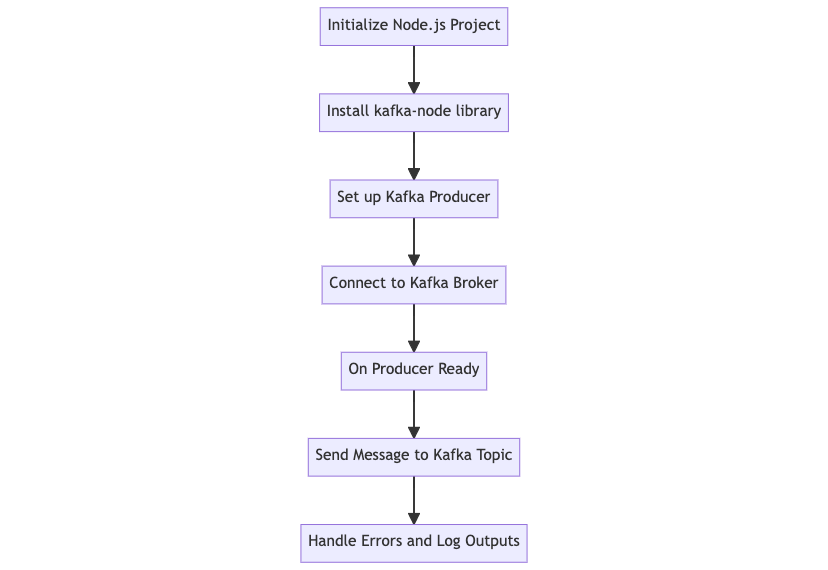
A: Initialize a Node.js project.
B: Install the kafka-node library.
C: Set up the Kafka producer.
D: Connect to the Kafka broker.
E: Wait for the producer to be ready.
F: Send a message to the Kafka topic.
G: Handle any errors and log the outputs.
Setting up the Node.js project
Initialize a new Node.js project and install the required library:
Writing the producer code:
Here:
- The
kafka-nodelibrary provides functionalities to communicate with Kafka using JavaScript. - We establish a connection to the Kafka broker running on
localhost:9092. - On the producer being ready, we send a message "Hello Kafka" to the
test-topic.
Kafka brokers and topic partitions
At the core of Kafka are topics, brokers, and partitions:
- Topics - communication channels where messages are sent.
- Brokers - individual Kafka servers that store data and serve client requests.
- Partitions - allow Kafka to horizontally scale as each partition can be hosted on a different server.
Creating a topic
The above command creates a topic named test-topic with 3 partitions. The replication factor of 1 means data is not duplicated across brokers. This setup is okay for local development but in production, you might want a higher replication factor for fault tolerance.
Creating Kafka consumers in JavaScript
While producers send messages to topics, consumers read these messages.
Writing the Consumer Code:
Here:
- We connect to the Kafka broker, similarly to the producer setup.
- The consumer listens to messages from
test-topicon partition 0. Every message received is printed to the console.
It's important to note that Kafka, with its extensive ecosystem, offers a wide range of settings and optimizations that are specifically designed for certain use cases. You'll occasionally need to adjust settings as you build and implement your write-intensive system to fit your particular requirements.
Implementing a system with tRPC
tRPC offers an easy way of creating typed end-to-end remote procedure calls. In the context of write-intensive systems, tRPC serves as a powerful tool to handle vast amounts of incoming data, transforming and ingesting it into the system.
Installation
Setting up a basic tRPC server
Here:
- tRPC uses routers to manage the different callable procedures.
- The
helloprocedure is a simple query that returns "Hello tRPC!". - The server starts and listens on port 4000.
Creating tRPC Procedures
Once you've set up your tRPC server, the next step involves defining procedures for various operations. Let's consider a use-case where the system should handle user registrations via Kafka events.
Defining a user registration procedure:
Here:
- We define a schema for user registration using
zod. This ensures type safety. - The
registerUsermutation will be called when we receive an event from Kafka.
Integrating tRPC with Kafka
With the tRPC procedure in place, the next step is to trigger it when a Kafka consumer reads a user registration event. The following diagram provides a step-by-step flow of how the Kafka consumer integrates with tRPC to handle user registration events.
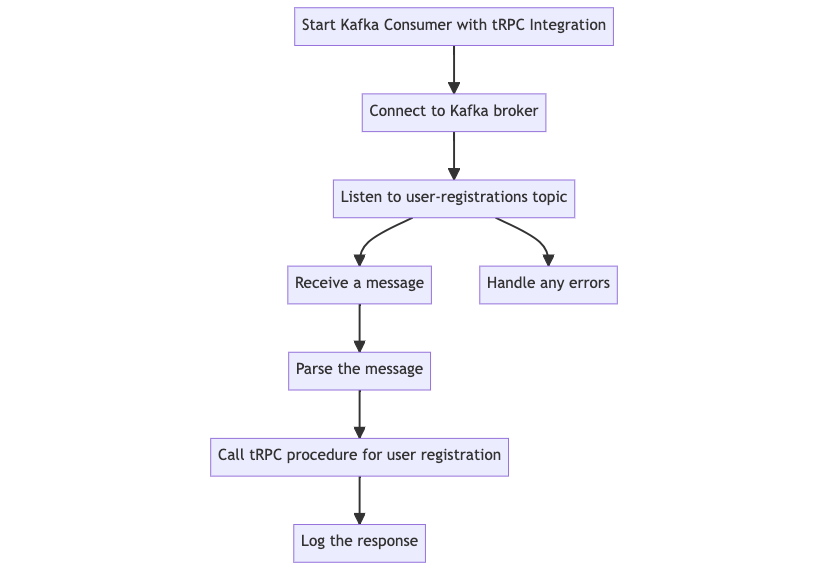
- Start Kafka consumer with tRPC integration - this is the initiation point where the Kafka consumer with tRPC integration begins.
- Connect to Kafka broker - establish a connection to the Kafka broker.
- Listen to user-registrations topic - the consumer starts listening to messages from the
user-registrationstopic. - Receive a message - a message is received from the topic.
- Parse the message - the received message is parsed to extract the user data.
- Call tRPC procedure for user registration - the parsed user data is used to call the tRPC procedure for registering the user.
- Log the response - the response from the tRPC procedure is logged.
- Handle any errors - any errors encountered during the process are handled.
Kafka Consumer with tRPC integration
Here:
- We consume messages from the
user-registrationstopic. On receiving a message, it gets parsed, and we directly call the tRPC procedure for registering a user. - This showcases a powerful concept: coupling event-driven architectures (via Kafka) with RPC operations (via tRPC), enhancing flexibility and directness in handling operations.
With this, we've taken a dive into setting up a system using tRPC, integrating it with Kafka, and setting the stage for a write-intensive workload. The powerful combination of tRPC's type-safety and Kafka's robustness can help ensure data accuracy, resilience, and scalability.
Optimizing the system for high-volume writes
Building a write-intensive system with Kafka and tRPC is just the start. To cater to high-volume writes, we need to optimize the system for performance, resilience, and scalability.
Batch processing with Kafka
Batch processing is a method where a set of data is processed and stored in a group, or batch, rather than individually. Kafka supports batch processing out of the box.
By setting batchSize, you're indicating the number of messages that should be batched together.
Asynchronous writes
To further improve throughput, consider producing messages asynchronously:
We're generating 1000 messages and sending them asynchronously to Kafka. This maximizes the utilization of resources and accelerates write operations.
Load balancing and partitioning in Kafka
To distribute the load, increase the number of topic partitions and consumers. Multiple consumers can read from different partitions simultaneously, parallelizing processing.
Error handling and retry mechanisms
Ensure your system is resilient by handling errors and retries:
In this code, if the producer encounters an error, the code retries sending the message after a 5-second delay. Incorporating exponential back-off and setting a max retry limit can further enhance this logic.
Optimizing a write-intensive system requires a blend of architectural decisions and configuration tweaks. Each optimization technique comes with its trade-offs, so understanding the requirements and constraints of the specific system is crucial. Whether it's increasing throughput with batch processing, ensuring data integrity with synchronous writes, or guaranteeing resilience with error handling, each technique has a role in ensuring the system performs optimally under high load.
Conclusion
Building a write-intensive system can be a complex task, requiring an understanding of various technologies, system design principles, and optimization techniques.
In this comprehensive guide, we dissected the art of constructing a write-intensive system using Kafka and tRPC. Kafka's prowess in high-volume data streaming paired with tRPC's type-safe and efficient APIs ensures a system that's both robust and performant. From foundational setups to advanced optimization techniques like batch processing and asynchronous writes, we've laid out a roadmap to navigate the complexities of such systems, helping you achieve resilience and peak performance.


