PlanetScale
At first glance, it might seem that PlanetScale is just another cloud-hosting for your database. However, it offers plenty of handy tools and services bundled into one interface. It eliminates the requirement of setting up and maintaining a bunch of server-side tools and configurations.
Aren Hovsepyan


- Website: planetscale.com
- Founded: 2018
- Total raised: $105M
Companies like Uber and Spotify use PlanetScale because it provides the scalability and fault tolerance needed for their demanding workloads without sacrificing the simplicity and ease of use of MySQL.
PlanetScale was founded in 2018 by the co-creators and maintainers of the Vitess open-source project.
What is PlanetScale
PlanetScale is a cloud-hosted and serverless database platform created on top of Vitess - a MySQL-compatible and cloud-native database. It combines many essential features of relational MySQL and the scalability of NoSQL databases. It has a built-in sharding feature that enables growing applications without explicit sharding logic.
PlanetScale allows you to set up a MySQL server in a matter of seconds. Some of the most prominent features are the automatic failover and backup capabilities. It lets a developer be ignorant about the underlying database topology. It means your application growth is not limited by the hardware resources and can automatically scale for larger throughput and handle automatic failover in the case of emergency.
Treat your database as code with branching
Alongside excellent scalability and high availability features, it provides a neat developer experience that allows for secure separation of staging data from production and easy data replication from a certain point in time. PlanetScale’s branching feature enables you to treat the database as code and create branches of the database from a certain point in time, like in Git.
It provides two branch types - development and production.
Both branch types create an isolated copy of your database schema. The development branch is intended for development and experimental purposes, as the name suggests. It becomes handy when you want to branch off your production environment to quickly test a new feature or create a hotfix for a bug in the database.
On the other hand, production branches are highly available databases tuned for production traffic. Most importantly, they are protected from direct schema mutations and include daily backups.
Note that by default, PlanetScale includes only the schema in your branches without your data copy. However, it also offers the Data Branching feature, which automatically creates a copy of both data and schema in a separate development branch.
Edge Functions and PlanetScale
With the popularity of Edge networks, there is a need to adjust database interfaces to be compatible with modern Edge runtimes. It gives a huge opportunity to increase the performance and decrease the latency of your application. Nowadays, Edge computing is a complementary part of many large-scale applications. With the help of Cloudflare Workers or Vercel Edge Functions, you can easily leverage a microservice architecture that improves the developer experience and application performance. However, a traditional centralized database server, where data queries and operations are handled by one or multiple machines, does not fit the new web model. Most database servers provide a TCP interface for communication between the application and the database. This acts a huge limitation when it comes to Edge networks, where for sake of security and performance we have an isolated environment that can invoke only HTTP requests.
Thus, PlanetScale introduces an Edge-compatible driver that can communicate with PlanetScale's globally distributed infrastructure via Fetch API.
Get your hands dirty
In this example, we will create a database that stores a dictionary of Navajo code talkers. Let’s bootstrap a simple Cloudflare Workers application where you can communicate with a database to add to and manipulate existing data.
Initialize Cloudflare Workers
First, you need to run `wrangler init` followed by your project name:
`wrangler init <PROJECT_NAME>`
You will be asked a couple of questions related to the newly created project.
- Choose to add a Git repository
- Initialize package.json
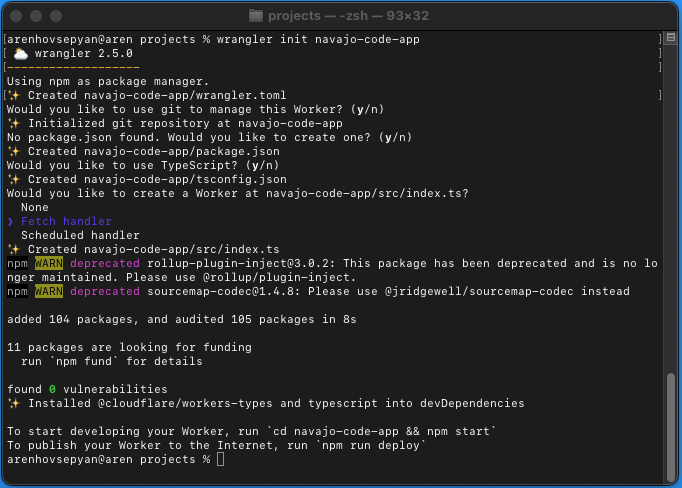
3. Choose to use TypeScript in this example.
The newly created application is going to have the following file structure
- src
- index.ts
- .gitignore
- package-lock.json | yarn.lock
- package.json
- tsconfig.json
- wrangler.toml
Next, you can run your workers application via the following command:
`wrangler dev`
Set up PlanetScale MySQL database and connect via Serverless driver
In order to connect to your database cluster, you need to install PlanetScale Serverless driver, which is created especially for Edge environments.
`npm install @planetscale/database`
Next, add the following code in `index.ts`, where you initialize the connection to the database cluster and call the content of the `codes` table.
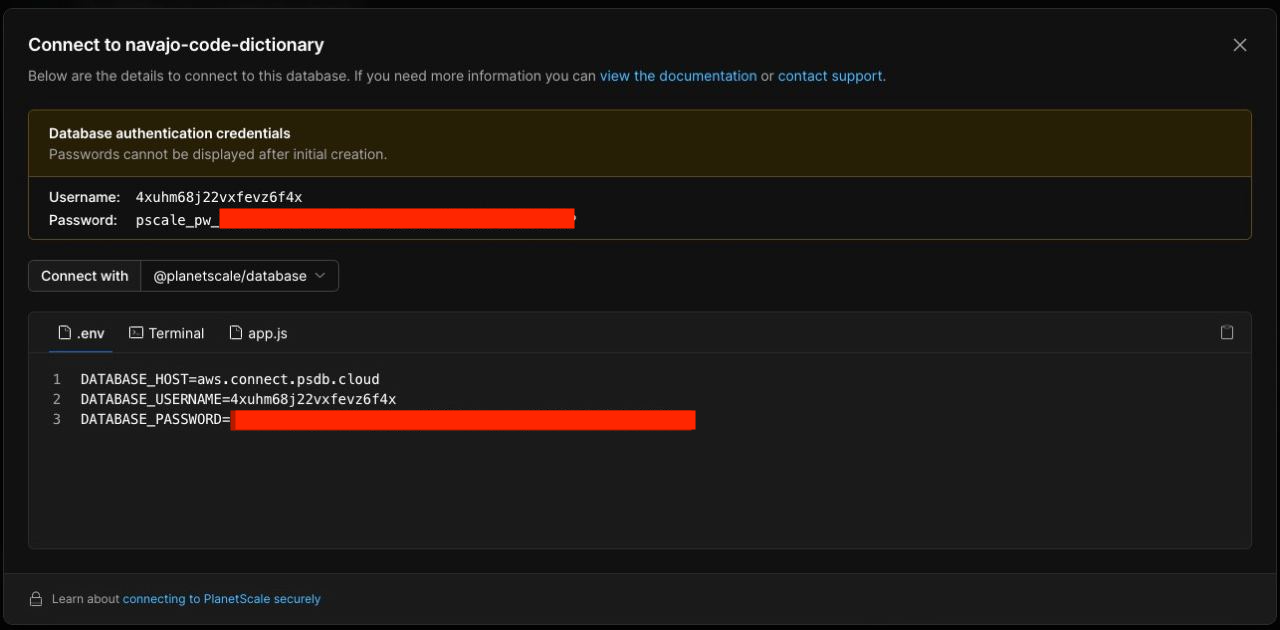
You can find credentials in the PlanetScale dashboard under the “Connect” button.
However, when you first run the workers endpoint, you will face an error because you have not set up the`codes` table yet.
Set up the table and insert the data
To store data in MySQL, you need to connect to your PlanetScale cluster via a CLI tool called `pscale`. You can find the installation manual in the following link.
- In the first step, you need to authorize your CLI tool session via `pscale auth login` command.
- Next, you need to connect to your server via the following command: `pscale shell navajo-code-dictionary main`. You can replace `navajo-code-dictionary` with your database name.
- At this stage, you are already in a MySQL environment where you can run standard SQL commands to create a table and insert the data.
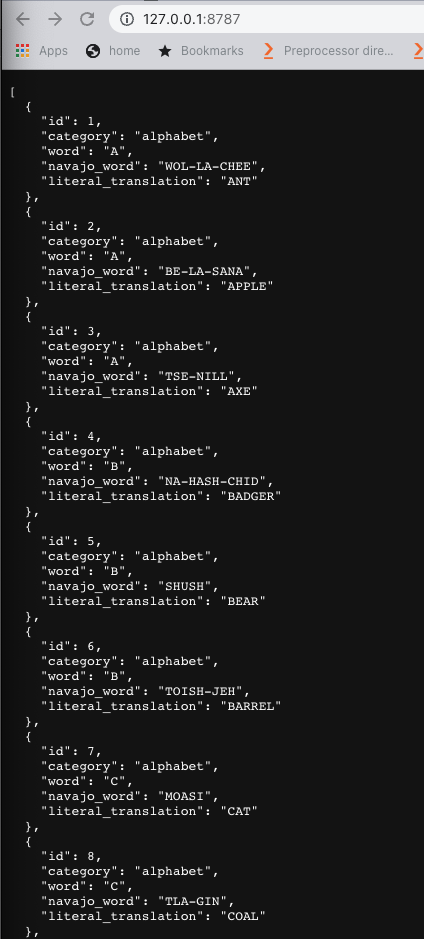
Exposing table content in JSON
After you’ve set up the table and populated it with data, you can call your worker endpoint and display the results.
Conclusion
The main idea behind PlanetScale is to provide developers with an easy way to scale applications without worrying about database scaling.
PlanetScale was created to solve the problems caused by existing solutions:
High costs – most companies pay more than $100 per month for database hosting, and the prices increase every year.
Inconvenient scaling – when your data grows, you need to add new servers manually or use third-party services (e.g., AWS RDS). Either way, it requires time and effort from developers and DevOps teams to manage this process properly.
Inconvenient management – most solutions require manual tuning of settings (e.g., cache parameters), which causes instability.





